
How prediction markets work? A complete technical guide
Published on

Prediction markets, popularized by platforms such as Polymarket, allow users to speculate on the outcome of future events through financial contracts. Behind their apparent simplicity lies a complex technical stack involving on-chain and off-chain architectures, order books, AMMs, oracles, dispute resolution, and liquidity management. In this complete guide, we explain how prediction markets work, their economic models, their risks, and why they could become a major infrastructure layer for financial information.
A definition of prediction markets
A prediction market is a financial instrument that allows participants to take positions on the outcome of uncertain future events. Participants buy, sell, or trade contracts whose final payout depends on whether or not a given real-world event occurs.
The price of these contracts can be interpreted as the implied probability of the event occurring: it reflects the aggregated conviction of participants at a given moment. Unlike polls or traditional forecasts, prediction markets rely on financial commitment, which incentivizes participants to express their opinions as rigorously as possible.
Poorly calibrated opinions lead to capital losses, while more accurate forecasts are rewarded. This is the essence of the prediction market model: monetizing individual convictions about real-world events and rewarding the best ones. This mechanism allows probabilities to emerge that, in many cases, prove more reliable than traditional methods.
Prediction markets have existed for several decades in different forms, particularly in academic or institutional contexts. The emergence of blockchain infrastructure marked a turning point by making it possible to automate contract settlement, make market rules transparent, and reduce reliance on centralized intermediaries.
The key event was the 2024 U.S. presidential election, where Polymarket truly became known to the general public by displaying probabilities that were often more accurate than most traditional polling institutes.
Behind this apparent simplicity, there is actually a wide range of technical choices involved in the design of a prediction market: how prices are formed (AMMs, order books, or hybrid models), market resolution mechanisms, the data sources used to determine outcomes, systems for handling debates or disputes, the types of markets supported, and the degree of openness in market creation.
These technical criteria are fundamental to understanding how prediction markets work, the differences between the players that exist today, and the evolution of the sector. This is what we will detail in the following sections.
Become Premium
Unlock all our research and get the right insights, at the right time.
Architecture of prediction market platforms
The architecture of a prediction market platform determines how markets are created, how orders are executed, how external data is integrated, and how payments are settled. These technical choices have a direct impact on the transparency and performance of the system, but also on its exposure within a regulatory framework.
Today, there are three main categories of architectures: fully on-chain, fully off-chain, and hybrid. Each relies on different trade-offs between decentralization, regulation, operational efficiency, and user experience.

Fully on-chain architectures
Fully on-chain platforms execute all their operations directly on a public blockchain: market creation, collateral deposit, price formation, market outcome determination, and final payout.
Market rules are encoded in smart contracts, which guarantees total transparency and full verifiability of operations. Users interact directly with the protocol through a wallet, without an intermediary.
This model was historically used by the first decentralized prediction markets, such as Augur or protocols built around Gnosis’s Conditional Token Framework. Today, it can be found on certain platforms such as Opinion, Limitless, or Probable.
- Advantages: transparent and intermediary-free execution, censorship resistance, flexibility, and potential composability with DeFi.
- Limitations: high transaction costs, dependency on blockchain performance, still-limited data sources, smart contract vulnerabilities, and regulatory uncertainty.
Fully off-chain architectures
On the opposite end, fully off-chain platforms rely on traditional centralized infrastructure. Market creation, order matching, user account management, and event resolution are handled on private servers with internal databases.
Users do not directly hold the assets used for betting and must trust the operator for settlement and proper contract execution. This model is similar to traditional betting platforms or centralized exchanges.
Regulated platforms such as Kalshi, Novig, ForecastEx, or Crypto.com Prediction Markets adopt this architecture in order to meet the legal requirements of their jurisdiction and guarantee faster and more reliable execution.
- Advantages: excellent performance and low latency, user experience close to Web2 standards, easier integration into jurisdictional regulatory frameworks.
- Limitations: lack of transparency, reliance on a trusted third party for fund custody and market resolution, less flexibility in available markets.
Hybrid architectures
Hybrid architectures attempt to combine the advantages of the two previous approaches. They generally rely on a clear separation between critical components requiring minimal trust (collateral management, settlement, contract creation) and those requiring performance (order matching, user interface, data aggregation).
In this model, orders can be matched off-chain for speed reasons, while final settlement and position creation are performed on-chain. This allows platforms to preserve cryptographic guarantees over funds while offering a smooth and scalable experience.
This is the architecture adopted by platforms such as Polymarket, where user order matching is optimized off-chain for most markets, just like trading, which can be done through off-chain signed orders (EIP-712), while outcome determination, settlement, and payouts are handled on-chain through smart contracts.
- Advantages: good compromise between performance and transparency, reduced on-chain costs, better user experience.
- Limitations: centralization points, greater technical complexity, smart contract vulnerabilities, and regulatory ambiguity.
Architecture choices and fundamental trade-offs
The choice of architecture is never neutral. It determines:
- the platform’s ability to scale,
- the level of trust users can place in the system,
- the ease of regulatory integration,
- and the nature of the markets that can be offered.
No architecture is universally superior. Fully on-chain platforms maximize sovereignty and transparency, off-chain models optimize efficiency and compliance, while hybrid architectures try to balance these two extremes.
These prediction market architecture choices directly impact liquidity and risk management issues for users, which we will address in the following sections.
Types of prediction contracts
Another defining feature of prediction markets lies in the variety of contracts they offer. Each contract type corresponds to a different way of expressing an opinion about an event, aggregating information, and structuring the final payout. The choice of format has a direct impact on liquidity, probability accuracy, and the technical complexity of the market.
Several major categories of prediction contracts are generally distinguished, each suited to specific use cases.
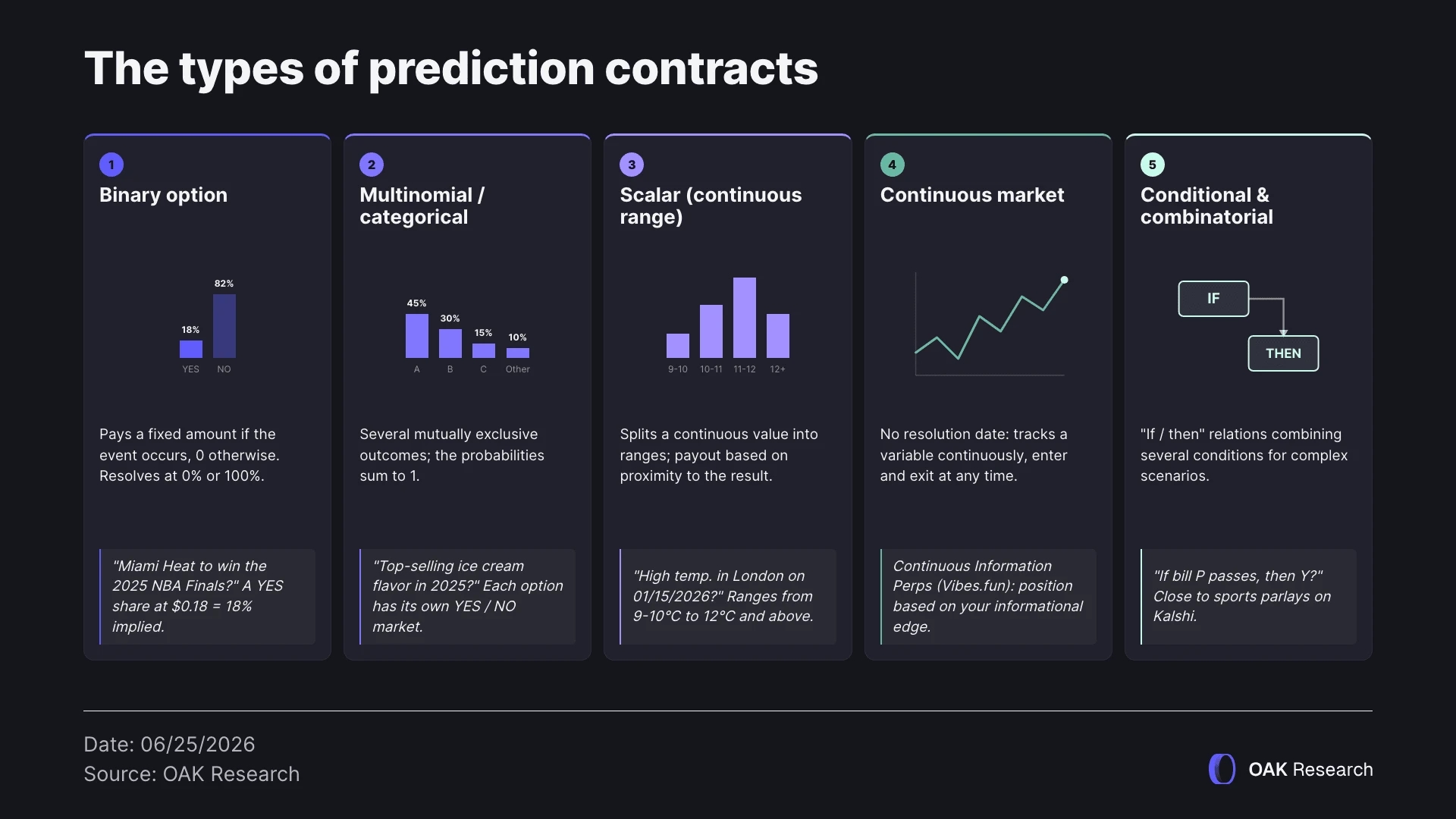
Binary options
The binary option is the simplest and most common form of prediction contract. The contract pays a fixed value (generally 1 unit) if the event occurs, and 0 otherwise. It therefore resolves discretely, at either 0% or 100%.
For example: “Will the Miami Heat win the 2025 NBA Finals?” (YES / NO).
If a YES share trades at $0.18, the market assigns an implied probability of 18% to that event.
This format is particularly effective for clearly defined, verifiable, and binary events (elections, sports results, regulatory decisions). Its simplicity makes it accessible to a broad audience and supports adoption, but it provides information limited to a single closed-ended question.
Multinomial or categorical markets
Multinomial markets extend the binary principle to several mutually exclusive outcomes. Each possible outcome has its own contract, and the sum of the implied probabilities of all outcomes must equal 1.
For example: “Which ice cream flavor will sell the most in 2025? (Chocolate / Vanilla / Strawberry / Other).”
Each flavor has its own YES/NO market with a corresponding price.
Liquidity is distributed across multiple outcomes, which makes price formation more complex. To maintain probability consistency, these markets generally rely on specific pricing mechanisms, often derived from the LMSR (Logarithmic Market Scoring Rule) model.
This type of contract captures richer information than a simple yes/no market, but it fragments liquidity and increases the technical complexity of the market, since the prices of the different outcomes must be continuously coordinated to avoid mathematical inconsistency.
Scalar markets (or continuous range markets)
Scalar markets allow a continuous numerical value to be divided into several intervals, making it possible to predict the outcome of an event through ranges (prices, scores, dates, quantities, etc.). The final payout depends on the proximity between the predicted value and the actual result.
For example: “What will be the highest temperature in London on January 15, 2026? (9-10°C / 10-11°C / 11-12°C / 12°C or higher).”
A participant expecting a high temperature could buy YES shares in the (11-12°C) and (12°C or higher) contracts.
Scalar markets are particularly useful for macroeconomic, financial, or demographic data. They allow an average estimate to be extracted, but also an implicit distribution of market expectations. In return, they require very precise resolution rules and reliable data sources.
Continuous markets
Unlike markets with a fixed maturity, continuous markets do not resolve on a specific date. They continuously track a variable over time, allowing participants to enter and exit positions at any price and at any time horizon, producing a fairly precise probability distribution.
Conceptually, this format is close to perpetual markets in crypto, with the notable difference that continuous prediction markets generally do not include leverage. This absence of leverage limits systemic risk, but also reduces capital efficiency.
One notable example is Continuous Information Perps, with Vibesdotfun being one of the main representatives. These allow traders to dynamically position themselves according to their informational edge, without waiting for a predefined resolution date.
Conditional and combinatorial markets
Conditional markets introduce if / then relationships. The contract payout depends both on the occurrence of a primary event and the occurrence of a secondary event.
For example: “If law P is passed, will Y happen?”
Combinatorial markets allow complex scenarios to be modeled by combining several conditions within a single contract. However, this creates major challenges in terms of liquidity, pricing, and resolution.
On Kalshi, around 80% of weekly volume comes from sports. The platform recently introduced a new contract format inspired by parlays in sports betting, where several conditions are combined into a single ticket, effectively creating true combinatorial markets.
Prediction market creation models
The market creation system on a platform defines who is allowed to launch new prediction markets, under what rules, and with what control mechanisms. This choice largely depends on the underlying architecture and the regulatory framework in which the platform operates.
This is an often underestimated parameter, yet it has a decisive impact on the diversity and quality of available markets, the risk of poorly defined rules and therefore bot spam, as well as the precision of event resolution methods.
Three main approaches are generally distinguished: permissioned, permissionless, and hybrid models.
Permissioned models
In a permissioned model, the creation of new markets is controlled by the platform operator. A centralized team decides which events can be listed, precisely defines the contract terms, and validates the sources used for resolution.
This model is mainly adopted by platforms operating within a strict regulatory framework. Kalshi is the most emblematic example: each market must comply with CFTC requirements, particularly to avoid insider trading risks, which imposes a rigorous selection of proposed events and a clear legal definition of the contracts.
- Advantages: higher quality of listed markets, more precise rule definitions, reduced dispute risk, and better regulatory compliance.
- Limitations: limited market diversity, slower innovation, full dependence on the operator for introducing new events, potentially overly strict rules for users.
Permissionless models
Conversely, permissionless models allow any user to create a market without prior authorization, provided they respect certain technical constraints (minimum collateral, formatting rules, security deposit, etc.).
This model is favored by decentralized platforms because it encourages experimentation, the emergence of niche markets, and the arrival of new users. The main representatives of this category are Opinion, XO Market, Manifold, and MyriadMarkets.
However, full openness creates specific problems: poorly formulated markets, ambiguous events, spam, or manipulation attempts. To address this, these platforms often integrate support and curation mechanisms for market creation, such as staking, community voting, or bonding curve systems applied to market creation.
- Advantages: strong market diversity, rapid innovation, alignment with decentralization principles.
- Limitations: risk of poorly defined markets, need for more complex governance mechanisms, higher exposure to disputes.
Hybrid models
Hybrid models logically sit between the two previous systems. Users can propose new markets, but these must be approved by governance or a committee before becoming accessible across the platform.
This approach makes it possible to broaden the range of available markets while maintaining a certain level of quality and consistency in definitions. It is increasingly used by platforms that want to preserve a stable user experience without sacrificing innovation.
This is notably the case with Polymarket, which does not allow users to directly create a new market through its interface, but encourages them to submit ideas in the #market-suggestion channel on its Discord server.
- Advantages: good balance between diversity and quality, reduced spam, better readability for users.
- Limitations: slower validation process, governance sometimes difficult to coordinate.
Price management in prediction markets
Price formation is the core engine of a prediction market. It determines how participants use the market to express their opinion, how individual views are aggregated into a usable implied probability, and how the market reacts to new information.
Unlike traditional financial markets, prediction markets must deal with unique assets: events that are difficult to predict, have a fixed resolution date, and require the probabilities of different outcomes to remain constantly balanced.
This requires specific pricing mechanisms designed to function even with limited liquidity. There are mainly three broad families of mechanisms: Automated Market Makers (AMMs), order books (CLOBs), and hybrid models.
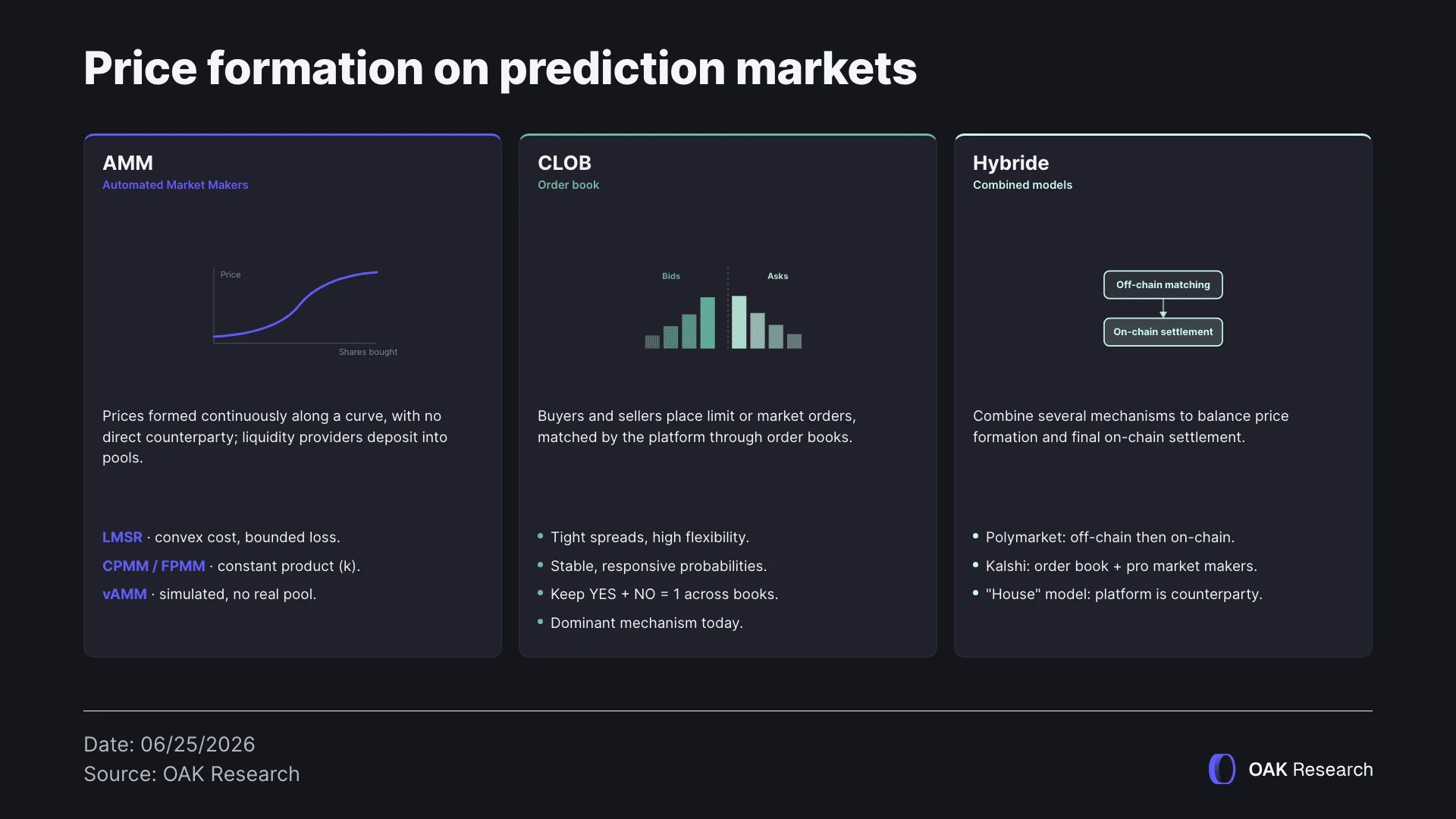
Automated Market Makers (AMM)
AMMs are mechanisms widely used in on-chain finance, particularly by decentralized exchanges. They allow prices to be formed continuously without requiring a direct counterparty between buyers and sellers. The price is determined by a mathematical function that evolves based on the positions taken by participants.
In practice, AMMs work by allowing liquidity providers to deposit capital into pools whose balance follows a pricing curve, with an algorithm based on mathematical formulas enabling continuous trading, even when there are few participants or when buy and sell orders do not need to be precisely matched.
This model is particularly well suited to prediction markets in their launch phase, when liquidity is insufficient to support an efficient order book. Polymarket initially adopted an AMM model in its early days, but this proved inefficient as the platform began to grow. It then migrated to an order book model (which we will discuss next), allowing for more accurate prices and deeper market liquidity.
After the launch of Uniswap V3 and the introduction of concentrated liquidity, several teams specialized in prediction markets began exploring what event trading could look like under this format. Here are the different AMM model variants currently used in some prediction markets.
- LMSR (Logarithmic Market Scoring Rule)
LMSR, introduced by Robin Hanson, is one of the most historically used models in prediction markets. It relies on a convex cost function that guarantees continuous price evolution and a bounded maximum loss for the market maker.
As traders buy shares of a given outcome, its price gradually rises toward 1, while the prices of other outcomes decrease. The key parameter is the liquidity factor, which controls market depth and price sensitivity to orders.
- CPMM / FPMM (Constant Product Market Makers)
FPMM is inspired by Uniswap V2 AMMs, with models that use a constant product relationship between the reserves of different outcomes (for example YES × NO = k). When traders buy YES shares, the pool rebalances and the price increases. Liquidity is real and deposited, which means the final payout depends on the reserves available in the pool.
They are simpler to implement and more intuitive, but they expose liquidity providers to significant risk: as the event approaches resolution, the curve becomes increasingly imbalanced, which amplifies potential losses at market settlement.
- vAMM (Virtual AMM)
vAMMs are essentially AMMs without a real liquidity pool, separating price formation from actual liquidity deposits. Pricing is simulated through a virtual curve, while collateral and settlement are managed separately.
This model reduces initial capital requirements, but introduces an additional risk: if parameters are poorly calibrated, the system can become unstable or produce prices that are not representative.
Order books (CLOB)
Most prediction markets today use an order book. Buyers and sellers place limit orders (buy or sell orders at a specific price) or market orders (orders executed immediately at the best available price). The platform then matches these orders with each other.
Order books are generally the best option for highly liquid markets with significant capitalization. They allow the tightest spreads and offer great flexibility to traders. This is precisely why order books are the most widely used mechanism for perpetual markets.
In prediction markets, for a given event, each contract (YES or NO) has its own order book, and prices directly reflect the balance between supply and demand. The additional challenge is preserving a continuous logic of “YES + NO = 1” between the two contracts, regardless of how their respective order books evolve.
In short, order books are now favored by platforms that have reached critical mass in terms of users and volume, because they produce probabilities that are more stable and more responsive to information.
Hybrid models
A hybrid liquidity model combines several trading mechanisms in order to balance price evolution and final order settlement. Instead of relying only on an AMM or only on an order book, some platforms use both.
For example, on Polymarket, order matching is performed off-chain, while settlement is handled on-chain. Kalshi’s liquidity model, although based on an order book, is also supported by an internal trading team and external professional market makers.
Some sports betting platforms also use a model where users bet against the platform itself. In this case, liquidity is provided directly by the “house,” meaning the platform itself acts as the counterparty to all bets. This model only works in markets where, statistically, users are mostly losing.
Prediction market resolution systems
The resolution system is one of the most technical components of a prediction market. It defines how a market outcome is verified, validated, and used to settle participants’ positions. It is a crucial component: even a very liquid and properly managed market loses all credibility among participants if its resolution is slow or disputed.
In practice, the resolution source is always explicitly defined when the market is created and displayed in its description. It specifies which source is authoritative, what data is used, and under what rules the event is considered resolved.
There is no universal model: platforms generally combine several approaches depending on the type of event, its degree of objectivity, and regulatory constraints. However, four major categories of resolution systems can be distinguished.
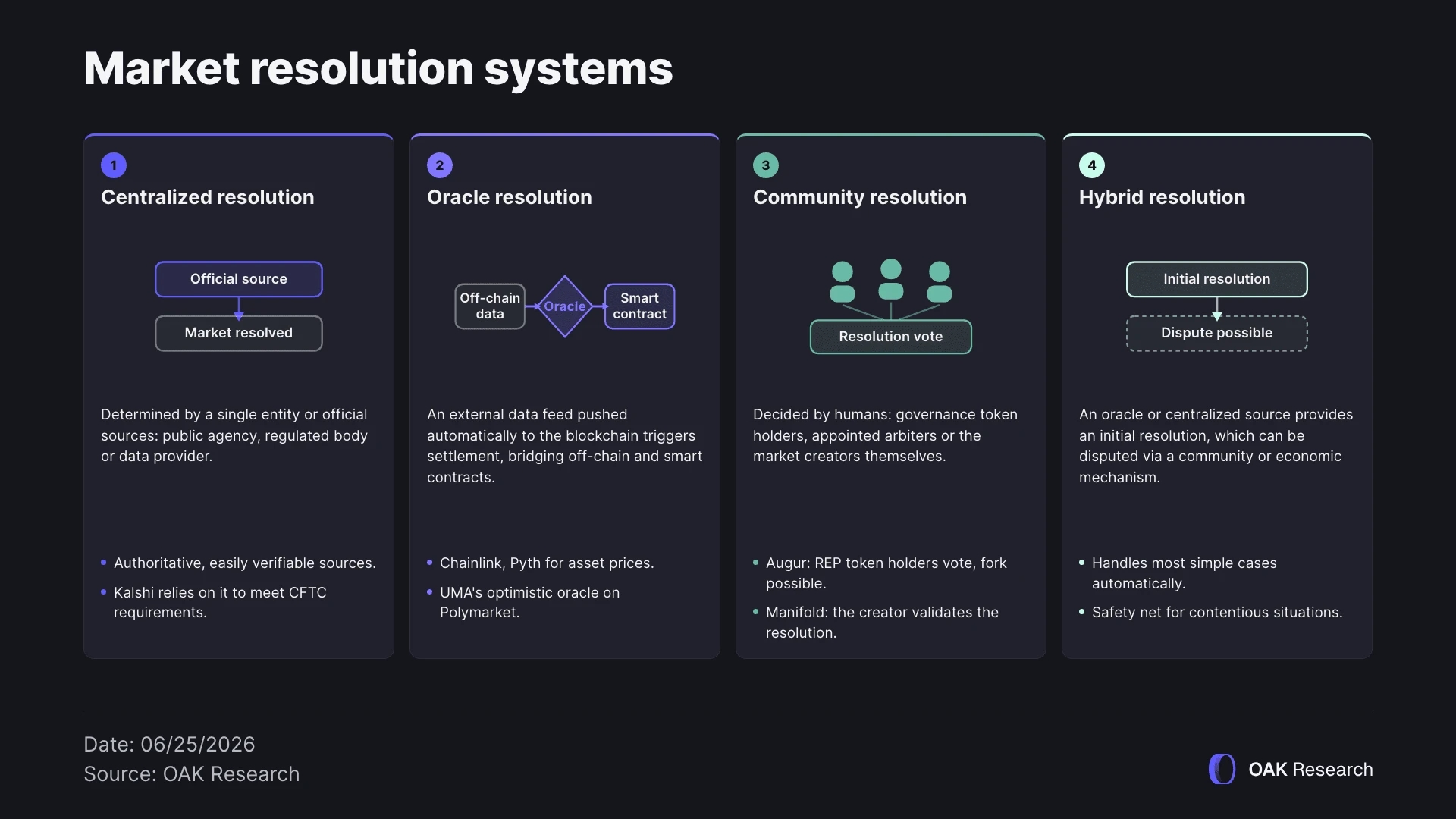
Centralized resolution
In a centralized resolution model, the market outcome is determined by a single entity or a limited set of official sources. This may be a government agency, a regulated body, a data provider, or a major news agency.
This model is widely used for everyday events (sports results, economic data, political decisions), because it relies on authoritative and easily verifiable sources. Human intervention is often minimal in this type of market.
Regulated platforms such as Kalshi rely exclusively on this type of resolution in order to meet CFTC requirements, although other unregulated players also use it (Limitless, for example). The rules are strict, the sources are clearly identified, and legal responsibility is assumed by the operator.
Oracle-based resolution
Oracle-based resolution consists of using an external data feed automatically transmitted to the blockchain in order to trigger contract settlement. The oracle acts as a bridge between the off-chain world (real-world data) and smart contracts. This model is particularly well suited to events based on quantifiable and standardized data, such as asset prices, rates, or certain economic metrics.
Decentralized oracles such as Chainlink or Pyth are the most widely used for markets linked to asset prices, especially in crypto, because they guarantee a high level of precision that supports better resolution. In other cases, platforms rely on optimistic oracles. This is notably the case for Polymarket, which uses UMA’s optimistic oracle. An asserter proposes a resolution and posts collateral; if no one disputes it within a given period, the outcome is considered valid.
Community or human resolution
In community resolution systems, the market outcome is determined by human actors: governance token holders, designated arbitrators, or market creators themselves. This model is mostly used when the event is difficult to strictly formalize or when it requires contextual assessment (subjective outcomes, ambiguous events, interpretation of a text).
Augur’s historical markets relied on this principle: REP token holders voted on the market outcome by participating in staking, with the possibility of triggering a fork in the event of major disagreement. On Manifold Markets, market creators often validate the resolution themselves.
Hybrid resolution
Hybrid models combine several of the previous approaches in order to balance automation and security. In practice, an oracle or centralized source provides an initial resolution, which can then be disputed through a community or economic mechanism.
This model is increasingly widespread because it allows the majority of simple cases to be handled efficiently while preserving a safety net for disputed situations. Today, it is the best model to ensure fast resolution while also maintaining a degree of flexibility.
Liquidity and economic constraints of prediction markets
Liquidity is one of the most important and complex challenges to manage for prediction markets. As with any financial market, it is essential to have enough liquidity to provide a good user experience and thereby attract a larger number of traders.
When liquidity is insufficient, prediction market adoption is mechanically limited, especially compared to perpetual markets, which offer deep liquidity and unlimited leverage.
However, unlike traditional financial markets, prediction markets depend on unique events, with an expiration date and a binary outcome. This specificity creates a major problem: market making activity, meaning providing liquidity to markets, is particularly risky and difficult to make profitable over time.
Why market making is difficult
In a prediction market, each contract mechanically converges toward a final value of 0 or 1 as resolution approaches. Unlike spot or perpetual markets, there is no natural mechanism to effectively hedge against the risk that part of a position falls to zero.
In other words, a market maker cannot neutralize exposure through another perfectly correlated instrument, because the underlying event is unique. As a reminder, in perpetual markets, market makers can hedge their positions with the spot market, and vice versa.
This means that providing liquidity to a prediction market amounts to accepting latent directional risk, which materializes as an unhedgeable gain or loss at resolution. By definition, the role of a market maker is to accept virtually no directional risk, even less so with such a low expected return over the long term.
Expiration and endgame risk
As the event approaches its conclusion, the market enters what is known as the endgame phase. Information becomes more asymmetric, traders take increasingly aggressive positions, and prices rapidly converge toward their final value.
For liquidity providers, this phase is particularly dangerous. In an AMM, the pricing curve becomes extremely imbalanced, causing the pool to accumulate almost exclusively the wrong side of the market. At resolution, this exposure results in a net loss that is often greater than the fees collected over the entire life of the market.
Even in an order book, market makers are forced to significantly widen spreads or remove liquidity to avoid being systematically picked off by better-informed traders or simply by a market resolving in the wrong direction.
Impossibility of hedging
In traditional financial markets, inventory risk can be managed through derivatives, correlated markets, or dynamic hedging strategies. In prediction markets, this option is largely nonexistent.
A market maker exposed to a political, regulatory, or sporting event has no equivalent asset available to offset risk. The exposure is binary, non-divisible, and non-transferable.
This impossibility of hedging explains why many purely algorithmic liquidity models, in some prediction markets, have failed over the long term or required significant subsidies to remain attractive.
Economic incentives and subsidies
Initially, to respond to these constraints, projects developed different approaches. For example, Gnosis created the Conditional Token Framework (CTF), which we discussed earlier, an advanced system that allows users to create, manage, and settle bets on future events. The model resembles the historical approach used by Augur, which was shut down in 2020.
It is based on event tokens divided into two outcomes, YES and NO. Traders can create (mint) both sides of a contract and sell one of them to gain exposure to the other. Since these tokens are issued as ERC-20s, they can be freely transferred and used across other applications, improving composability and overall liquidity.
For its part, Polymarket initially adopted an AMM-based model with liquidity providers, but quickly abandoned it in favor of an order book because of the problems mentioned above. However, the order book does not solve the market maker hedging problem.
Therefore, to compensate for these constraints and still attract market makers, many platforms rely on artificial incentives: liquidity subsidies, rewards programs, or agreements with professional desks.
These mechanisms make it possible to launch viable markets in the short term, but raise questions about their long-term sustainability: liquidity that disappears as soon as incentives end cannot provide a proper user experience. However, on the most popular markets, this is currently the most advanced solution.
Liquidity is not only a question of user experience or displayed volume. It directly determines the quality of the information produced by the market. An illiquid market is easier to manipulate, more sensitive to isolated orders, and less representative of the real consensus. Conversely, deep liquidity allows prices to quickly adjust to new information and reflect a probability that is more stable and more usable.
It is precisely this relationship between liquidity, information, and economic incentives that explains why most prediction markets fail to produce reliable data at scale. These constraints naturally lead to another key issue for prediction markets: the systemic risks specific to these mechanisms, which we will analyze in the next section.
Systemic risks specific to prediction markets
Beyond liquidity constraints, prediction markets involve a series of systemic risks specific to them. These risks are not accidental: they emerge directly from the structure of the markets, the nature of the events handled, and the resolution mechanisms used.
Insider trading and adverse selection
The engine of prediction markets relies on aggregating distributed information. But this strength also becomes a weakness when information is highly asymmetric. Traders with a real informational advantage (insider trading) can use it to profit from less informed participants or market makers. This phenomenon, also known as adverse selection, is structurally amplified in prediction markets.
As an event approaches resolution, information becomes increasingly obvious to some actors, who position themselves accordingly, while pricing mechanisms continue to provide liquidity under the same conditions to everyone else. Market makers then systematically find themselves on the wrong side of the trade.
Over time, this dynamic discourages liquidity providers, which degrades market depth and further reinforces information asymmetry.
Manipulation in illiquid markets
Illiquid prediction markets are particularly vulnerable to price manipulation. An actor with moderate capital can significantly move the displayed probability without necessarily holding superior information.
This manipulation can be motivated by several objectives:
- influencing public or media opinion,
- creating a false market signal,
- attracting other participants before taking the opposite position,
- or exploiting poorly calibrated resolution or reward systems.
Even though most manipulations are quickly corrected in deep markets, they can have a disproportionate impact in niche or low-participation markets, especially when probabilities are reused by external dashboards or media outlets.
Exploitation of inefficiencies by bots
Prediction markets are particularly sensitive to the exploitation of inefficiencies by bots. Unlike on-chain perpetual markets, they do not permanently benefit from professional market makers whose role is to eliminate every exploitable arbitrage opportunity.
Prediction markets work differently. The price of a contract does not depend only on internal supply and demand, but on the evolution of an external event whose information arrives with some delay. This information is then integrated into the market through oracles, official data sources, or indirect update mechanisms.
This time lag creates an obvious attack surface for low-latency bots. In markets based on real-time external data (BTC price over a short window, sports score, weather conditions, interim results), some bots manage to capture information at the source before it is reflected in the prediction market.
The bot can then take a position in the prediction market before the implied probability adjusts, capturing almost risk-free value. This is not a better forecasting model, but a purely temporal advantage. In addition to this information asymmetry, there is a second layer of inefficiencies, specific to prediction market order books themselves.
In some markets, especially very short binary markets (for example: “Will BTC be above X in 15 minutes?”), event volatility leads many users to react emotionally, which tends to temporarily imbalance the order book.
It can then happen that, over a short time window, the sum of the YES and NO contract prices is no longer equal to 1, but lower. In that specific case, a bot can buy both sides of the market simultaneously and lock in a certain profit, regardless of the final outcome.
Combined with fast execution and privileged access to the external information source, this strategy allows some automated actors to be “more informed” than standard users, even without having a fundamental advantage on the event itself.
These dynamics explain why prediction markets today are particularly noisy with bots seeking to exploit the smallest microstructure flaw, at the expense of user experience and sometimes the quality of the signal produced by the market. In response to these behaviors, Polymarket introduced variable fees on 15-minute crypto markets.
Event ambiguity and disputes
Another major systemic risk lies in poor market definition. A poorly worded event, an ambiguous source, or an insufficiently precise condition can lead to disputes at resolution.
Unlike traditional financial markets, where the underlying asset is generally a standardized price or asset, prediction markets deal with real-world events, often complex and contextual.
Disputes have several negative effects:
- they delay position settlement,
- they degrade user trust,
- they introduce legal and economic uncertainty,
- and they can be exploited opportunistically by certain actors.
This is why the most mature platforms place disproportionate importance on writing market rules, sometimes at the expense of the diversity of events offered.
Governance and capture risks
In decentralized or hybrid models, governance mechanisms themselves can become a source of risk. If market resolution or dispute validation depends on a governance token, that token can be accumulated or coordinated by a small group of actors.
This opens the door to governance capture attacks, where the resolution of a market no longer reflects the reality of the event, but the economic interests of an artificial majority.
Even when these attacks are costly, their mere possibility weakens the credibility of the system, especially for high-stakes markets.
Informational feedback loops
Finally, prediction markets can influence the events they are supposed to predict. When a probability becomes widely visible and publicized, it can alter the behavior of the actors involved.
This feedback phenomenon is particularly sensitive in political, financial, or regulatory markets. A high probability can influence strategic decisions, votes, arbitrage, or public positioning.
This does not make markets useless, but it requires acknowledging that they are not simply neutral observers. They actively participate in the informational ecosystem they model.
Conclusion
Prediction markets are not simply on-chain betting platforms. They are complete technical systems whose performance depends on a set of architecture choices, pricing mechanisms, market creation models, resolution methods, and liquidity strategies.
This guide shows that the main difficulty does not lie in creating a market as such, but in assembling all of its components coherently. A market can be theoretically well designed and fail in practice if its liquidity is insufficient, if its resolution is contestable, if its contracts are poorly worded, or if its microstructure is too easily exploitable.
Conversely, platforms that succeed in producing a reliable and usable signal are generally those that master the trade-offs: choosing events that are simple to resolve, defining unambiguous rules, limiting low-latency attack surfaces, structuring sustainable liquidity incentives, and integrating regulatory reality into product design.
In the short term, most innovation in the sector is focused on three areas: improving liquidity without permanent subsidies, making resolution more reliable through better-calibrated oracles and dispute mechanisms, and reducing the impact of bots and market inefficiencies on user experience.
As these building blocks mature, prediction markets may evolve from a primarily speculative product into a robust informational infrastructure capable of aggregating probabilities on real-world events with an unprecedented level of transparency and auditability.
The following sections of this series will analyze the current landscape of players, their implementation choices, and the most credible paths toward large-scale adoption.
Become Premium
Unlock all our research and get the right insights, at the right time.


